Identify Distribution Strategy¶
Pick distribution key¶
The first step in migrating to Citus is identifying suitable distribution keys and planning table distribution accordingly. In multi-tenant applications this will typically be an internal identifier for tenants. We typically refer to it as the “tenant ID.” The use-cases may vary, so we advise being thorough on this step.
For guidance, read these sections:
We are happy to help review your environment to be sure that the ideal distribution key is chosen. To do so, we typically examine schema layouts, larger tables, long-running and/or problematic queries, standard use cases, and more.
Identify types of tables¶
Once a distribution key is identified, review the schema to identify how each table will be handled and whether any modifications to table layouts will be required. We typically advise tracking this with a spreadsheet, and have created a template you can use.
Tables will generally fall into one of the following categories:
- Ready for distribution. These tables already contain the distribution key, and are ready for distribution.
- Needs backfill. These tables can be logically distributed by the chosen key, but do not contain a column directly referencing it. The tables will be modified later to add the column.
- Reference table. These tables are typically small, do not contain the distribution key, are commonly joined by distributed tables, and/or are shared across tenants. A copy of each of these tables will be maintained on all nodes. Common examples include country code lookups, product categories, and the like.
- Local table. These are typically not joined to other tables, and do not contain the distribution key. They are maintained exclusively on the coordinator node. Common examples include admin user lookups and other utility tables.
Consider an example multi-tenant application similar to Etsy or Shopify where each tenant is a store. Here’s a portion of a simplified schema:
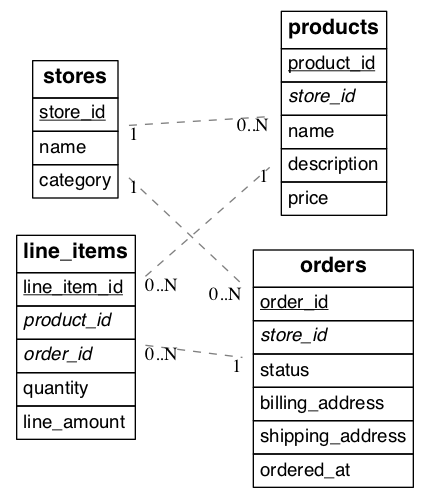
(Underlined items are primary keys, italicized items are foreign keys.)
In this example stores are a natural tenant. The tenant id is in this case the store_id. After distributing tables in the cluster, we want rows relating to the same store to reside together on the same nodes.
Prepare Tables for Migration¶
Once the scope of needed database changes is identified, the next major step is to modify the data structure. First, existing tables requiring backfill are modified to add a column for the distribution key.
Add distribution keys¶
In our storefront example the stores and products tables have a store_id and are ready for distribution. Being normalized, the line_items table lacks a store id. If we want to distribute by store_id, the table needs this column.
-- denormalize line_items by including store_id
ALTER TABLE line_items ADD COLUMN store_id uuid;
Be sure to check that the distribution column has the same type in all tables, e.g. don’t mix int and bigint. The column types must match to ensure proper data colocation.
Include distribution column in keys¶
Citus cannot enforce uniqueness constraints unless a unique index or primary key contains the distribution column. Thus we must modify primary and foreign keys in our example to include store_id.
Here are SQL commands to turn the simple keys composite:
BEGIN;
-- drop simple primary keys (cascades to foreign keys)
ALTER TABLE products DROP CONSTRAINT products_pkey CASCADE;
ALTER TABLE orders DROP CONSTRAINT orders_pkey CASCADE;
ALTER TABLE line_items DROP CONSTRAINT line_items_pkey CASCADE;
-- recreate primary keys to include would-be distribution column
ALTER TABLE products ADD PRIMARY KEY (store_id, product_id);
ALTER TABLE orders ADD PRIMARY KEY (store_id, order_id);
ALTER TABLE line_items ADD PRIMARY KEY (store_id, line_item_id);
-- recreate foreign keys to include would-be distribution column
ALTER TABLE line_items ADD CONSTRAINT line_items_store_fkey
FOREIGN KEY (store_id) REFERENCES stores (store_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_product_fkey
FOREIGN KEY (store_id, product_id) REFERENCES products (store_id, product_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_order_fkey
FOREIGN KEY (store_id, order_id) REFERENCES orders (store_id, order_id);
COMMIT;
Thus completed, our schema will look like this:
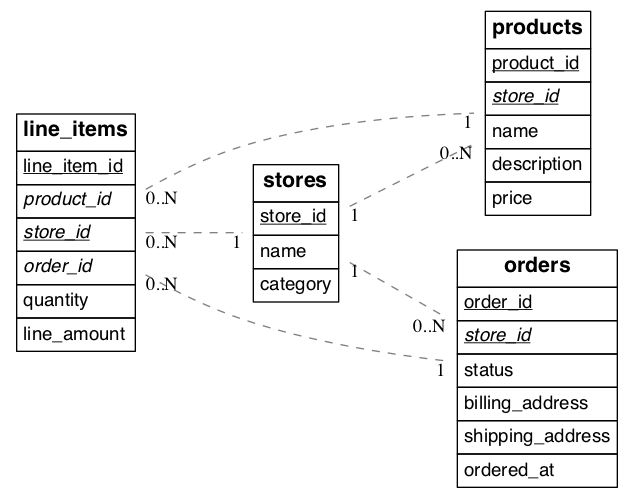
(Underlined items are primary keys, italicized items are foreign keys.)
Be sure to modify data flows to add keys to incoming data.
Backfill newly created columns¶
Once the schema is updated, backfill missing values for the tenant_id column in tables where the column was added. In our example line_items requires values for store_id.
We backfill the table by obtaining the missing values from a join query with orders:
UPDATE line_items
SET store_id = orders.store_id
FROM line_items
INNER JOIN orders
WHERE line_items.order_id = orders.order_id;
The application and other data ingestion processes should be updated to include the new column for future writes. More on that in the next section.