Prepare Application for Citus
Set up Development Citus Cluster
When modifying the application to work with Citus, you’ll need a database to test against. Follow the instructions to set up a Single-Node Citus of your choice.
Next dump a copy of the schema from your application’s original database and restore the schema in the new development database.
# get schema from source db
pg_dump \
--format=plain \
--no-owner \
--schema-only \
--file=schema.sql \
--schema=target_schema \
postgres://user:pass@host:5432/db
# load schema into test db
psql postgres://user:pass@testhost:5432/db -f schema.sql
The schema should include a distribution key (“tenant id”) in all tables you wish to distribute. Before pg_dumping the schema, be sure you have completed the step Prepare Source Tables for Migration from the previous section.
Include distribution column in keys
Citus cannot enforce uniqueness constraints unless a unique index or primary key contains the distribution column. Thus we must modify primary and foreign keys in our example to include store_id.
Some of the libraries listed in the next section are able to help migrate the database schema to include the distribution column in keys. However, here is an example of the underlying SQL commands to turn the simple keys composite in the development database:
BEGIN;
-- drop simple primary keys (cascades to foreign keys)
ALTER TABLE products DROP CONSTRAINT products_pkey CASCADE;
ALTER TABLE orders DROP CONSTRAINT orders_pkey CASCADE;
ALTER TABLE line_items DROP CONSTRAINT line_items_pkey CASCADE;
-- recreate primary keys to include would-be distribution column
ALTER TABLE products ADD PRIMARY KEY (store_id, product_id);
ALTER TABLE orders ADD PRIMARY KEY (store_id, order_id);
ALTER TABLE line_items ADD PRIMARY KEY (store_id, line_item_id);
-- recreate foreign keys to include would-be distribution column
ALTER TABLE line_items ADD CONSTRAINT line_items_store_fkey
FOREIGN KEY (store_id) REFERENCES stores (store_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_product_fkey
FOREIGN KEY (store_id, product_id) REFERENCES products (store_id, product_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_order_fkey
FOREIGN KEY (store_id, order_id) REFERENCES orders (store_id, order_id);
COMMIT;
Thus completed, our schema from the previous section will look like this:
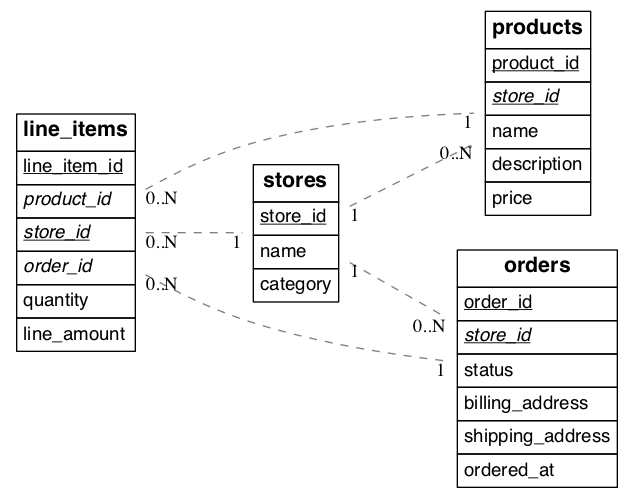
(Underlined items are primary keys, italicized items are foreign keys.)
Be sure to modify data flows to add keys to incoming data.
Add distribution key to queries
Once the distribution key is present on all appropriate tables, the application needs to include it in queries. The following steps should be done using a copy of the application running in a development environment, and testing against a Citus back-end. After the application is working with Citus we’ll see how to migrate production data from the source database into a real Citus cluster.
Application code and any other ingestion processes that write to the tables should be updated to include the new columns.
Running the application test suite against the modified schema on Citus is a good way to determine which areas of the code need to be modified.
It’s a good idea to enable database logging. The logs can help uncover stray cross-shard queries in a multi-tenant app that should be converted to per-tenant queries.
Cross-shard queries are supported, but in a multi-tenant application most queries should be targeted to a single node. For simple select, update, and delete queries this means that the where clause should filter by tenant id. Citus can then run these queries efficiently on a single node.
There are helper libraries for a number of popular application frameworks that make it easy to include a tenant id in queries:
It’s possible to use the libraries for database writes first (including data ingestion), and later for read queries. The activerecord-multi-tenant gem for instance has a write-only mode that will modify only the write queries.
Other (SQL Principles)
If you’re using a different ORM than those above, or doing multi-tenant queries more directly in SQL, follow these general principles. We’ll use our earlier example of the ecommerce application.
Suppose we want to get the details for an order. Distributed queries that filter on the tenant id run most efficiently in multi-tenant apps, so the change below makes the query faster (while both queries return the same results):
-- before
SELECT *
FROM orders
WHERE order_id = 123;
-- after
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- <== added
The tenant id column is not just beneficial – but critical – for insert statements. Inserts must include a value for the tenant id column or else Citus will be unable to route the data to the correct shard and will raise an error.
Finally, when joining tables make sure to filter by tenant id too. For instance here is how to inspect how many “awesome wool pants” a given store has sold:
-- One way is to include store_id in the join and also
-- filter by it in one of the queries
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
-- Equivalently you omit store_id from the join condition
-- but filter both tables by it. This may be useful if
-- building the query in an ORM
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p ON l.product_id = p.product_id
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
AND p.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
Enable Secure Connections
Clients should connect to Citus with SSL to protect information and prevent man-in-the-middle attacks.
Check for cross-node traffic
With large and complex application code-bases, certain queries generated by the application can often be overlooked, and thus won’t have a tenant_id filter on them. Citus’ parallel executor will still execute these queries successfully, and so, during testing, these queries remain hidden since the application still works fine. However, if a query doesn’t contain the tenant_id filter, Citus’ executor will hit every shard in parallel, but only one will return any data. This consumes resources needlessly, and may exhibit itself as a problem only when one moves to a higher-throughput production environment.
To prevent encountering such issues only after launching in production, one can set a config value to log queries which hit more than one shard. In a properly configured and migrated multi-tenant application, each query should only hit one shard at a time.
During testing, one can configure the following:
-- adjust for your own database's name of course
ALTER DATABASE citus SET citus.multi_task_query_log_level = 'error';
Citus will then error out if it encounters queries which are going to hit more than one shard. Erroring out during testing allows the application developer to find and migrate such queries.
During a production launch, one can configure the same setting to log, instead of error out:
ALTER DATABASE citus SET citus.multi_task_query_log_level = 'log';
The configuration parameter section has more info on supported values for this setting.