Migrating an existing relational store to Citus sometimes requires adjusting the schema and queries for optimal performance. Citus extends PostgreSQL with distributed functionality, but it is not a drop-in replacement that scales out all workloads. A performant Citus cluster involves thinking about the data model, tooling, and choice of SQL features used.
Migration tactics differ between the two main Citus use cases of multi-tenant applications and real-time analytics. The former requires fewer data model changes so we’ll begin there.
Multi-tenant Data Model¶
Citus is well suited to hosting B2B multi-tenant application data. In this model application tenants share a Citus cluster and a schema. Each tenant’s table data is stored in a shard determined by a configurable tenant id column. Citus pushes queries down to run directly on the relevant tenant shard in the cluster, spreading out the computation. Once queries are routed this way they can be executed without concern for the rest of the cluster. These queries can use the full features of SQL, including joins and transactions, without running into the inherent limitations of a distributed system.
This section will explore how to model for the multi-tenant scenario, including necessary adjustments to the schema and queries.
Schema Migration¶
Transitioning from a standalone database instance to a sharded multi-tenant system requires identifying and modifying three types of tables which we may term per-tenant, reference, and global. The distinction hinges on whether the tables have (or reference) a column serving as tenant id. The concept of tenant id depends on the application and who exactly are considered its tenants.
Consider an example multi-tenant application similar to Etsy or Shopify where each tenant is a store. Here’s a portion of a simplified schema:
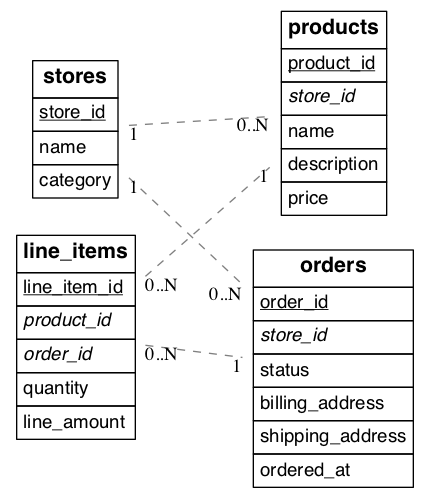
(Underlined items are primary keys, italicized items are foreign keys.)
In our example each store is a natural tenant. This is because storefronts benefit from dedicated processing power for their customer data, and stores do not need to access each other’s sales or inventory. The tenant id is in this case the store id. We want to distribute data in the cluster in such a way that rows from the above tables in our schema reside on the same node whenever the rows share a store id.
The first step is preparing the tables for distribution. Citus requires that primary keys contain the distribution column, so we must modify the primary keys of these tables and make them compound including a store id. Making primary keys compound will require modifying the corresponding foreign keys as well.
In our example the stores and products tables are already in perfect shape. The orders table needs slight modification: updating the primary and foreign keys to include store_id. The line_items table needs the biggest change. Being normalized, it lacks a store id. We must add that column, and include it in the primary key constraint.
Here are SQL commands to accomplish these changes:
BEGIN;
-- denormalize line_items by including store_id
ALTER TABLE line_items ADD COLUMN store_id uuid;
-- drop simple primary keys (cascades to foreign keys)
ALTER TABLE products DROP CONSTRAINT products_pkey CASCADE;
ALTER TABLE orders DROP CONSTRAINT orders_pkey CASCADE;
ALTER TABLE line_items DROP CONSTRAINT line_items_pkey CASCADE;
-- recreate primary keys to include would-be distribution column
ALTER TABLE products ADD PRIMARY KEY (store_id, product_id);
ALTER TABLE orders ADD PRIMARY KEY (store_id, order_id);
ALTER TABLE line_items ADD PRIMARY KEY (store_id, line_item_id);
-- recreate foreign keys to include would-be distribution column
ALTER TABLE line_items ADD CONSTRAINT line_items_store_fkey
FOREIGN KEY (store_id) REFERENCES stores (store_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_product_fkey
FOREIGN KEY (store_id, product_id) REFERENCES products (store_id, product_id);
ALTER TABLE line_items ADD CONSTRAINT line_items_order_fkey
FOREIGN KEY (store_id, order_id) REFERENCES orders (store_id, order_id);
COMMIT;
When the job is complete our schema will look like this:
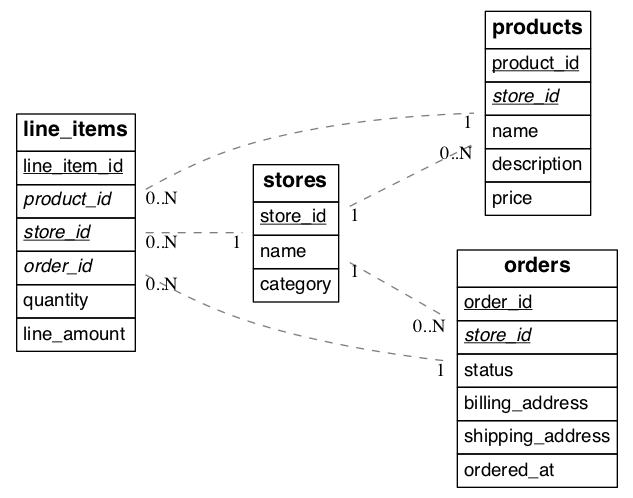
(Underlined items are primary keys, italicized items are foreign keys.)
We call the tables considered so far per-tenant because querying them for our use case requires information for only one tenant per query. Their rows are distributed across the cluster according to the hashed values of their tenant ids.
There are other types of tables to consider during a transition to Citus. Some are system-wide tables such as information about site administrators. We call them global tables and they do not participate in join queries with the per-tenant tables and may remain on the Citus coordinator node unmodified.
Another kind of table are those which join with per-tenant tables but which aren’t naturally specific to any one tenant. We call them reference tables. Two examples are shipping regions and product categories. We advise that you add a tenant id to these tables and duplicate the original rows, once for each tenant. This ensures that reference data is co-located with per-tenant data and quickly accessible to queries.
Backfilling Tenant ID¶
Once the schema is updated and the per-tenant and reference tables are distributed across the cluster it’s time to copy data from the original database into Citus. Most per-tenant tables can be copied directly from source tables. However line_items was denormalized with the addition of the store_id column. We have to “backfill” the correct values into this column.
We join orders and line_items to output the data we need including the backfilled store_id column. The results can go into a file for later import into Citus.
-- This query gets line item information along with matching store_id values.
-- You can save the result to a file for later import into Citus.
SELECT orders.store_id AS store_id, line_items.*
FROM line_items, orders
WHERE line_items.order_id = orders.order_id
To learn how to ingest datasets such as the one generated above into a Citus cluster, see Ingesting, Modifying Data (DML).
Query Migration¶
To execute queries efficiently for a specific tenant Citus needs to route them to the appropriate node and run them there. Thus every query must identify which tenant it involves. For simple select, update, and delete queries this means that the where clause must filter by tenant id.
Suppose we want to get the details for an order. It used to suffice to filter by order_id. However once orders are distributed by store_id we must include that in the where filter as well.
-- before
SELECT * FROM orders WHERE order_id = 123;
-- after
SELECT * FROM orders WHERE order_id = 123 AND store_id = 42;
Likewise insert statements must always include a value for the tenant id column. Citus inspects that value for routing the insert command.
When joining tables make sure to filter by tenant id. For instance here is how to inspect how many awesome wool pants a given store has sold:
-- One way is to include store_id in the join and also
-- filter by it in one of the queries
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
-- Equivalently you omit store_id from the join condition
-- but filter both tables by it. This may be useful if
-- building the query in an ORM
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p ON l.product_id = p.product_id
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
AND p.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75'
Real-Time Analytics Data Model¶
In this model multiple worker nodes calculate aggregate data in parallel for applications such as analytic dashboards. This scenario requires greater interaction between Citus nodes than the multi-tenant case and the transition from a standalone database varies more per application.
In general you can distribute the tables from an existing schema by following the advice in Query Performance Tuning. This will provide a baseline from which you can measure and interatively improve performance. For more migration guidance please contact us.