Determining Application Type¶
Running efficient queries on a Citus cluster requires that data be properly distributed across machines. This varies by the type of application and its query patterns.
There are broadly two kinds of applications that work very well on Citus. The first step in data modeling is to identify which of them more closely resembles your application:
Multi-Tenant Application
These are typically SaaS applications that serve other companies, accounts, or organizations. Most SaaS applications are inherently relational. They have a natural dimension on which to distribute data across nodes: just shard by tenant_id.
Citus enables you to scale out your database to millions of tenants without having to re-architect your application. You can keep the relational semantics you need, like joins, foreign key constraints, transactions, ACID, and consistency.
- Examples: Websites which host store-fronts for other businesses, such as a digital marketing solution, or a sales automation tool.
- Characteristics: Queries relating to a single tenant rather than joining information across tenants. This includes OLTP workloads for serving web clients, and OLAP workloads that serve per-tenant analytical queries. Having dozens or hundreds of tables in your database schema is also an indicator for the multi-tenant data model.
Scaling a multi-tenant app with Citus also requires minimal changes to application code. We have support for popular frameworks like Ruby on Rails and Django.
Real-Time Analytics
Applications needing massive parallelism, coordinating hundreds of cores for fast results to numerical, statistical, or counting queries. By sharding and parallelizing SQL queries across multiple nodes, Citus makes it possible to perform real-time queries across billions of records in under a second.
- Examples: Customer-facing analytics dashboards requiring sub-second response times.
- Characteristics: Few tables, often centering around a big table of device-, site- or user-events and requiring high ingest volume of mostly immutable data. Relatively simple (but computationally intensive) analytics queries involving several aggregations and GROUP BYs.
Distributing Data¶
If your situation resembles either case above then the next step is to decide how to shard your data in the Citus cluster. As explained in the Concepts section, Citus assigns table rows to shards according to the hashed value of the table’s distribution column. The database administrator’s choice of distribution columns needs to match the access patterns of typical queries to ensure performance.
Multi-Tenant Apps¶
The multi-tenant architecture uses a form of hierarchical database modeling to distribute queries across nodes in the distributed cluster. The top of the data hierarchy is known as the tenant id, and needs to be stored in a column on each table. Citus inspects queries to see which tenant id they involve and routes the query to a single worker node for processing, specifically the node which holds the data shard associated with the tenant id. Running a query with all relevant data placed on the same node is called Table Co-Location.
The following diagram illustrates co-location in the multi-tenant data model. It contains two tables, Accounts and Campaigns, each distributed by account_id. The shaded boxes represent shards, each of whose color represents which worker node contains it. Green shards are stored together on one worker node, and blue on another. Notice how a join query between Accounts and Campaigns would have all the necessary data together on one node when restricting both tables to the same account_id.
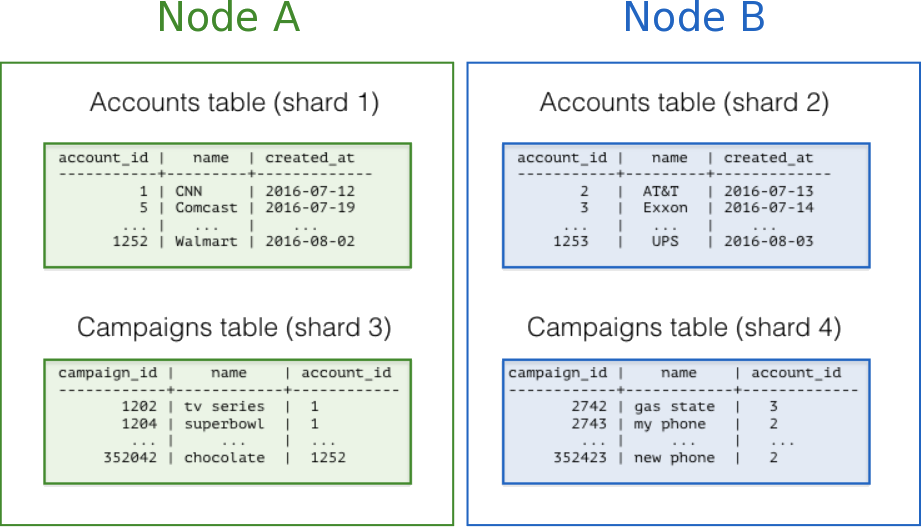
To apply this design in your own schema the first step is identifying what constitutes a tenant in your application. Common instances include company, account, organization, or customer. The column name will be something like company_id or customer_id. Examine each of your queries and ask yourself: would it work if it had additional WHERE clauses to restrict all tables involved to rows with the same tenant id? Queries in the multi-tenant model are usually scoped to a tenant, for instance queries on sales or inventory would be scoped within a certain store.
Best Practices¶
- Partition distributed tables by a common tenant_id column. For instance, in a SaaS application where tenants are companies, the tenant_id will likely be company_id.
- Convert small cross-tenant tables to reference tables. When multiple tenants share a small table of information, distribute it as a reference table.
- Restrict filter all application queries by tenant_id. Each query should request information for one tenant at a time.
Read the Multi-tenant Applications guide for a detailed example of building this kind of application.
Real-Time Apps¶
While the multi-tenant architecture introduces a hierarchical structure and uses data co-location to route queries per tenant, real-time architectures depend on specific distribution properties of their data to achieve highly parallel processing.
We use “entity id” as a term for distribution columns in the real-time model, as opposed to tenant ids in the multi-tenant model. Typical entites are users, hosts, or devices.
Real-time queries typically ask for numeric aggregates grouped by date or category. Citus sends these queries to each shard for partial results and assembles the final answer on the coordinator node. Queries run fastest when as many nodes contribute as possible, and when no single node must do a disproportionate amount of work.
Best Practices¶
- Choose a column with high cardinality as the distribution column. For comparison, a “status” field on an order table with values “new,” “paid,” and “shipped” is a poor choice of distribution column because it assumes only those few values. The number of distinct values limits the number of shards that can hold the data, and the number of nodes that can process it. Among columns with high cardinality, it is good additionally to choose those that are frequently used in group-by clauses or as join keys.
- Choose a column with even distribution. If you distribute a table on a column skewed to certain common values, then data in the table will tend to accumulate in certain shards. The nodes holding those shards will end up doing more work than other nodes.
- Distribute fact and dimension tables on their common columns. Your fact table can have only one distribution key. Tables that join on another key will not be co-located with the fact table. Choose one dimension to co-locate based on how frequently it is joined and the size of the joining rows.
- Change some dimension tables into reference tables. If a dimension table cannot be co-located with the fact table, you can improve query performance by distributing copies of the dimension table to all of the nodes in the form of a reference table.
Read the Real Time Dashboards guide for a detailed example of building this kind of application.