MX (Beta)¶
Citus MX is a new version of Citus that adds the ability to use hash-distributed tables from any node in a Citus cluster, which allows you to scale out your query throughput by opening many connections across all the nodes. This is particularly useful for performing small reads and writes at a very high rate in a way that scales horizontally. Citus MX is currently available in private beta on Citus Cloud.
Architecture¶
In the Citus MX architecture, all nodes are PostgreSQL servers running the Citus extension. One node is acting as coordinator and the others as data nodes, each node also has a hot standby that automatically takes over in case of failure. The coordinator is the authoritative source of metadata for the cluster and data nodes store the actual data in shards. Distributed tables can only be created, altered, or dropped via the coordinator, but can be queried from any node. When making changes to a table (e.g. adding a column), the metadata for the distributed tables is propagated to the workers using PostgreSQL’s built-in 2PC mechanism and distributed locks. This ensures that the metadata is always consistent such that every node can run distributed queries in a reliable way.
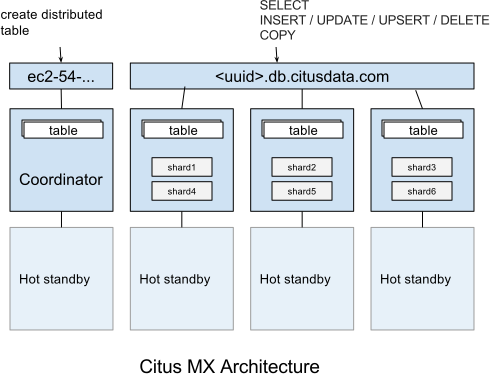
Citus MX uses PostgreSQL’s own streaming replication, which allows a higher rate of writes on the shards as well as removing the need to perform all writes through a single leader node to ensure linearizability and consistency. From the Citus perspective, there is now only a single replica of each shard and it does not have to keep multiple replicas in sync, since streaming replication handles that. In the background, we monitor every node and automatically fail over to a hot standby in case of a failure.
Data Access¶
In Citus MX you can access your database in one of two ways: Either through the coordinator which allows you to create or change distributed tables, or via the data URL, which routes you to one of the data nodes on which you can perform regular queries on the distributed tables. These are also the nodes that hold the shards, the regular PostgreSQL tables in which the data is stored.
Supported operations on the coordinator are: Create/drop distributed table, shard rebalancer, DDL, DML, SELECT, COPY.
Supported operations on the data URL are: DML, SELECT, COPY.
If you connect to the data URL using psql and run \d, then you will see all the distributed tables and some of the shards. Importantly, distributed tables are the same from all nodes, so it does not matter to which node you are routed when using the data URL when querying distributed tables. When performing a query on a distributed table, the right shard is determined based on the filter conditions and the query is forwarded to the node that stores the shard. If a query spans all the shards, it is parallelised across all the nodes.
For some advanced usages, you may want to perform operations on shards directly (e.g. add triggers). In that case, you can connect to each individual worker node rather than using the data URL. You can find the worker nodes hostnames by running SELECT * FROM master_get_active_worker_nodes() from any node and use the same credentials as the data URL.
A typical way of using MX is to manually set up tables via the coordinator and then making all queries via the data URL. An alternative way is to use the coordinator as your main application back-end, and use the data URL for data ingestion. The latter is useful if you also need to use some local PostgreSQL tables. We find both approaches to be viable in a production setting.
Scaling Out a Raw Events Table¶
A common source of high volume writes are various types of sensors reporting back measurements. This can include software-based sensors such as network telemetry, mobile devices, or hardware sensors in Internet-of-things applications. Below we give an example of how to set-up a write-scalable events table in Citus MX.
Since Citus is an PostgreSQL extension, you can use all the latest PostgreSQL 9.5 features, including JSONB and BRIN indexes. When sensors can generate different types of events, JSONB can be useful to represent different data structures. Brin indexes allow you to index data that is ordered by time in a compact way.
To create a distributed events table with a JSONB column and a BRIN index, we can run the following commands:
$ psql postgres://citus:pw@coordinator-host:5432/citus?sslmode=require
CREATE TABLE events (
device_id bigint not null,
event_id uuid not null default uuid_generate_v4(),
event_time timestamp not null default now(),
event_type int not null default 0,
payload jsonb,
primary key (device_id, event_id)
);
CREATE INDEX event_time_idx ON events USING BRIN (event_time);
SELECT create_distributed_table('events', 'device_id');
Once the distributed table is created, we can immediately start using it via the data URL and writes done on one node will immediately be visible from all the other nodes in a consistent way.
$ psql postgres://citus:pw@data-url:5432/citus?sslmode=require
citus=> INSERT INTO events (device_id, payload)
VALUES (12, '{"temp":"12.8","unit":"C"}');
Time: 3.674 ms
SELECT queries that filter by a specific device_id are particularly fast, because Citus can route them directly to a single worker and execute them on a single shard.
$ psql postgres://citus:pw@data-url:5432/citus?sslmode=require
citus=> SELECT event_id, event_time, payload FROM events WHERE device_id = 12 ORDER BY event_time DESC LIMIT 10;
Time: 4.212 ms
As with regular Citus, you can also run analytical queries which are parallelized across the cluster:
citus=>
SELECT minute,
min(temperature)::decimal(10,1) AS min_temperature,
avg(temperature)::decimal(10,1) AS avg_temperature,
max(temperature)::decimal(10,1) AS max_temperature
FROM (
SELECT date_trunc('minute', event_time) AS minute, (payload->>'temp')::float AS temperature
FROM events WHERE event_time >= now() - interval '10 minutes'
) ev
GROUP BY minute ORDER BY minute ASC;
Time: 554.565
The ability to perform analytical SQL queries combined with high volume data ingestion uniquely positions Citus for real-time analytics applications.
An important aspect to consider is that horizontally scaling out your processing power ensures that indexes don’t necessarily become an ingestion bottleneck as your application grows. PostgreSQL has very powerful indexing capabilities and with the ability to scale out you can almost always get the desired read- and write-performance.
Limitations Compared to Citus¶
All Citus 6.2 features are supported in Citus MX with the following exceptions:
Append-distributed tables currently cannot be made available from workers. They can still be used in the traditional way, with queries going through the coordinator. However, append-distributed tables already allowed you to Bulk Copy (250K - 2M/s).
When performing writes on a hash-distributed table with a bigserial column via the data URL, sequence numbers are no longer monotonic, but instead have the form <16-bit unique node ID><48-bit local sequence number> to ensure uniqueness. The coordinator node always has node ID 0, meaning it will generate sequence numbers as normal. Serial types smaller than bigserial cannot be used in distributed tables.